
The Internet – More like an 18th century frigate than the U.S.S. Enterprise
 It’s always fun to be reminded how vulnerable the web can be, but if its ropy as a whole, how do you keep an eye on the bits you and your suppliers depend upon?
It’s always fun to be reminded how vulnerable the web can be, but if its ropy as a whole, how do you keep an eye on the bits you and your suppliers depend upon?
First a look at the current state of internet affairs. Roland Dobbins summed it up nicely in a recent BBC Technology news article
“This may come as a surprise to non-specialists who view the internet as a high-tech affair comparable to the bridge of the USS Enterprise of Star Trek fame,” he said. “In actuality, the internet is more akin to an 18th century Royal Navy frigate, with a lot of running about, climbing, shouting, and tugging on ropes required to maintain the desired course and speed.“
He was talking about the August 12th screw up, when Verizon accidentally added 15 thousand extra routes to the list of ways round the internet. Although they consolidated those routes back down to a much smaller number very quickly, the fallout, in terms of widespread slow to no internet performance (affecting sites including Amazon, Ebay and LinkedIN), lasted for a number of hours.
It boiled down to a hardware limitation in some older Cisco routers. They choke (link to a technical take on the BGP routing related cause) if asked to deal with more than 512k routes. The 15k extra Verizon ones were enough to trigger this kind of upset in a subset of the net, but this pinch point was just a preview of the more general capacity squeeze in the router-verse. Those most savvy are actually welcoming this as a prod to get enthusiastic about required hardware and configuration changes, but it has an attractive whiff of doom about it that’s caught the the attention of soundbite merchants. Cue it’s very own scary thing name (a fairly benign one by many standards);
512k Day
Duh, Duh Duuuuuuh. Wikipedia had a page dedicated to it within 24 hours and as we speak new consultancy brochures are being churned out with these words front and center.
It is NOT, as the BBC mistakenly said, a ‘bug’. Nor is it, as other commentators have gleefully proclaimed, “the new Y2k”. It’s just old hardware and folk have known about this possibility for a while.
IPs dwindle and sharks attack while kitties and movies explode
The majority of internet addresses are still underpinned by IPv4 (numbers in 12 digit format xxx.xxx.xxx.xxx sit behind website names and internet connected devices, signposting the destination for outbound and return traffic), but the available permutations have almost run out (we’ve known this was likely for over 30 years). IPv6, the replacement with billions more addressing options, launched on 6th June 2012. Use has doubled year on year, but the roll out is very much slower than wanted or needed because piecemeal replacement of hardware doesn’t really work. This graphic (opens a PDF) shows progress and Ben Parr gives a good plain English overview of IPv4, IPv6 and the planned transition here.
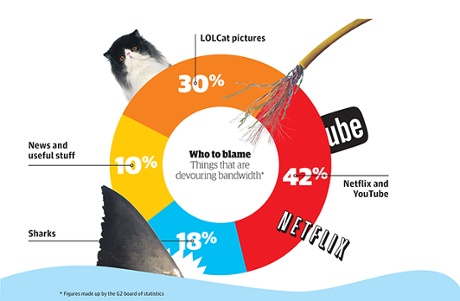
What’s Eating The Internet: Photo: The Guardian http://www.theguardian.com/technology/shortcuts/2014/aug/15/internet-broken-sharks-netflix-cables
Then there’s all the other ‘stuff’;
Netflix, YouTube and similar video streaming has grown so large that some ISPs (most notably Verizon and Comcast) are charging to maintain usable service levels. The justification being the high and increasing cost of maintaining sufficient bandwidth for all customers.
Then there’s the Internet of things. Folk monitoring your fridge, car, central heating and personal fitness. Fighting your website for an address on the web.
As for kittens, human nature is a strange thing. The number of webpages dedicated to stuff like kitty pics and videos is utterly ginormous…go figure.
And finally those sharks – No, ‘shark’ isn’t another macho name for a piece of malware, I’m talking about actual sharks. Apparently they’re being annoyed by the magnetic field generated by the big intercontinental undersea internet pipes and they’re chewing on them.
For a broader look at available bandwidth and what’s using it up (including competing social media sites and growth of mobile traffic), there’s another more detailed graphic from LifeHack.org
So what about your corner of the web world?
To get straight to the point – I suspect most of you are not asking the right questions, or demanding enough clarity during supplier selection, due diligence, contract negotiations or on-going governance.
Just one aspect of the challenge – how far do you go with due diligence when it comes to the quality of connectivity between you, your suppliers, their suppliers and the internet? A tongue in cheek example:

Your primary contractor has a high speed rail link with a fleet of entirely reliable, pristine trains, plus a secondary rail spur (in case there are the wrong kind of leaves on the line). It connects directly to a state of the art data center. The one you toured while negotiating the contract.
You know about, but don’t visit, their downstream content provider, served by a four lane, generally free-flowing highway and a fleet of well-maintained juggernauts. Behind those scenes is the dual-carriageway to the next bolt on service, with journey time dictated by top speed of their fleet of Vectras.
Before too long you find out there’s one crucial little piece of functionality, an innocuous little thing hooking the bigger value-add bits together, delivered via a dirt track winding down the side of a ravine. A track only passable by donkey. Perky energetic little donkeys, but donkeys nonetheless.
What’s the point, isn’t cloud availability doomed?
 The simple answer is no, not right now. Cisco routers can be rejigged or replaced so they can handle more routes, IPv6 is getting there and more, bigger and shark-proof pipes are in the offing to handle more cats and movies. However you still have to keep a close eye on internet availability and how it matches your requirements if you plan to rely on cloud solutions being there when you need them.
The simple answer is no, not right now. Cisco routers can be rejigged or replaced so they can handle more routes, IPv6 is getting there and more, bigger and shark-proof pipes are in the offing to handle more cats and movies. However you still have to keep a close eye on internet availability and how it matches your requirements if you plan to rely on cloud solutions being there when you need them.
So between Duh Duh Duuuuuuuh…512 Day, dwindling IP addresses, kittens, Netflix, sharks and run of the mill technical and human error generated outages, how the heck can you keep abreast of things impacting your cloud services?
Putting it bluntly YOU shouldn’t have to. Your service providers should. With the odd exception (like some hybrid solutions) maintaining the speed, reliability and capacity of cloud related connections is the responsibility of your suppliers.
That doesn’t mean you don’t have to keep your own house in order. You need to be able to identify bottlenecks in your own network before yelling at service providers, so if you haven’t got something in place already, it’s worth looking at available network monitoring tools. Depending on the size and complexity of your network there are some free tools available, usually minus uber attractive interfaces and reports. Alternatively, if you’re after an enterprise solution you could start with Gartner’s Magic Quadrant. It gives an overview of their best rated solutions. Handy to understand functionality available, but there has been some dispute about how unbiased ratings are.
Back into cloud service selection and contract reality
SLAs. Oh yes, most of you will have SLAs. Something over 95% up time etc etc. Great, keep those, but what have you done to confirm the supplier is capable of meeting those now and in the ever more squashed future of the internet? Here are some of the questions that spring to mind;
- If relevant (if they host web services), what is their current capability / rollout plan for IPv6?
- What is their recent history of slow performance and /or outages?
- What is their future strategy for coping with service and traffic growth?
- Can their ISP satisfy their current and future demand without impacting your contracted costs?
- Do they have clear and transparent sight of connectivity status for all of the connections they depend upon for their directly provided services and ditto for all of their downstream partners?
- Historically, how quickly have they been notified of or spotted incidents and how nimbly have they been able to respond and get fixes in place? Understanding their dependencies on others is vital.
Crucially, above all else, what contingency and resilience is built-in to the provided service, because, as this article eloquently explores, things will go bang. It’s how that’s mitigated and dealt with that counts.
The only feasible way to tackle most of this, (based on my experience dealing with a 2000 strong supplier population for a FTSE 100 company), is to dig deep into your primary supplier’s own supplier governance and incident management. Attempts to directly engage downstream partners will either be blocked, or consume all time available for other assessment activity.
The industry is crying out for a standardized assessment regime including concrete benchmarks for adequacy for a rational range of people, process and technology controls, but we are a country mile away from that being a reality. No two sets of client requirements are the same (part of the problem), but with an assured level of security, continuity and recovery capability, more risk averse firms could just assess round the edges.
Until something like that gains acceptance (perhaps based on ISO27k, the CSA STAR program, 20 Critical Security Controls, Cyber Essentials or something else) you can chose how much effort you make to satisfy yourself about the quality of connectivity provided now and whether that’s maintainable over time. Making sure, whatever that quality is, it lets you realize expected commercial and operational benefits.
For more advice and links to in-depth info about embedding security and business continuity into your cloud procurement activity, perhaps have a look at my related post “The Game Of Clouds – How Do You Procure and Stay Secure”