- 1.1 The media backdrop
- 1.2 The Crux: a.k.a what the GDPR really says about security
- 1.3 Security as source of privacy risks: security as a legitimate interest, IP addresses as personal data, and profiling in a security context.
and now in part two:
- 2.1 Encryption: Its mandatory and/or negates the need to apply other controls
- 2.2 ISO27001 certification = GDPR compliance
- 2.3 Existing security related risk management: Is it fit for privacy purposes?
to be followed in part three by:
- 3.3 Pseudonymisation or Anonymisation: Do they negate the need for GDPR compliance?
- 3.4 Personal data breaches: It’s all about the fines
- 3.5 Privacy is dead, so why bother?
2.1 Encryption: It’s mandatory and/or negates the need to apply other controls
Nope and/or absolutely not.
Encryption is undoubtedly a vital tool, but there is no mandated requirement for encryption in the GDPR. The GDPR doesn’t mandate ANY specific controls. It mentions a couple, like pseudonymisation and encryption, but it is all about control selection based upon your local risks. As I said in the first instalment that should, ideally, resemble the foundation of your existing security strategy, or whatever you have that passes for a ‘Beyond Firefighting’ type plan.
Rendering data unintelligible is an incredibly effective mitigation for post breach data related harm to both data subjects and the organisation, but it in no way negates the need to apply other security and data protection controls.
Encryption is only as effective as your control over credentials, colleagues, computers, and keys
Risks associated with any unencrypted access remain. A significant portion of internal and externally initiated compromises involve phishing, stealing, socially engineering, brute forcing, or otherwise obtaining valid credentials. Alternatively you might get compromised using emailed, downloaded, or physically installed malware that operates within the logged on user’s session. In both of those cases anything the rightful password owner can access, the attacker can also access. So yeah, not a massive amount of compromise scenarios are hampered by crypto. Have it, do it, don’t make it up yourself, and keep a tight rein on keys, but don’t over-egg that management report on its risk mitigation powers,
I’m far enough away from the coal face now that I check my technical homework, so I asked the twitter community to estimate how frequently encryption would act to prevent or hinder an attack or misuse. This was the response from Gabe Bassett, one of the key folk who crunches the annual Verizon Data Breach and Incident numbers.

Of course that view is subject to the same caveats as any analysis of data from multiple independent sources, but suffice to say encryption is NOT a privacy panacea.
Do you have an encryption strategy?
It should be viewed in the context of your entire risk universe (this 2017 Ponemon Global Encryption Trends Study reports that only 41% of surveyed businesses have an encryption strategy). Here are some of the non-trivial steps and inputs for a sustainable encryption plan:
- Data discovery and categorisation: What is worth encrypting and where is it (the point at which many planning attempts fail, or initial plans get unsustainably out of hand).
- Performance: Have you got high frequency/availability data transactions that will be impacted by encryption? What is the risk equation for those data sets?
- Implementation: Removable devices, laptops, web certificates, VPN, and other data transfers – done, but what about other data in scope? How would you effectively encrypt big data stores, cloud hosted data, backups? Would you even want to? How does the job break down between you and partners or suppliers? What are the interdependent systems? Where, for operational and security sake, do you need to decrypt? Can it break down into phases based on more and less risky assets? Will you be able to constantly and carefully manage expectations about those scope adjustments and costs?
- Budget: Where is the balancing benefit? How much focus do you place on post breach mitigation vs understanding threats, minimising the attack surface, and ensuring you minimise data collected and treat people fairly once you have it? Can budget, like implementation, break down into phases?
- Maintenance: How do you keep on top of IT changes, business process changes, and new supply arrangements that introduce new encryption requirements? How do you keep an effective eye on key management, evolving threats, evolving encryption standards, and admin access?
If planning to embark on a more detailed justification and plan for encryption usage you might find some of the stuff in NIST-175a handy. It goes through considerations for Federal government cryptography implementation, but it’s not difficult to overlay with a local data classification and risk profile.
2.2 ISO27001 certification = GDPR compliance
Nope.
More diplomatically: Nope, but it helps, because the Information Security Management System (ISMS), described in ISO27001, represents a robust way to scope, assess, articulate, document, and manage risks associated with all aspects of organisational security, including personal data security.
Article 5(2) is too often ignored and is arguably one of the biggest GDPR challenges:

An ISMS gives organisations a great head start to tackle it BUT the usual scope of controls (see ISO27002 sections pictured below), excludes the vast majority of required procedural control in the GDPR (e.g. ensuring appropriate lawful bases for processing, managing subject rights, minimising data collected, and developing means to effectively update data, return data, erase data, or restrict processing if required to do so).
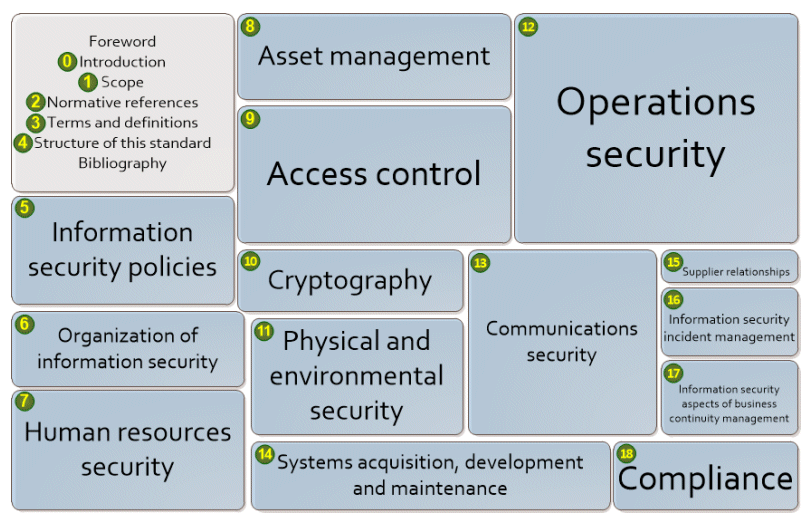
GRC specialists are also well aware that an ISMS provides a wrapper for good security, but evidence you have met an ISO27k standard doesn’t prove you have effectively mitigated your security risks. You can get an ISO27001 certificate even if many controls are broken, as long as you have all elements of the ISMS documented and you can show assessors a plan to reduce outstanding risks.
In addition, that only applies to your chosen scope. Many ISO27001 certificates only apply to discrete business units or departments. Leaving whole swathes of personal data out of the mix, especially, given typical security focus, employee data.
If you are after an ISO type standard to help shape a wider world of personal information management, why not check out the new GDPRed British Standard BS10012:2017 for a Personal Information Management System (needless to say you need to pay for it). Just like ISO27k it’s going to be control agnostic, but for organisations who like the ISO way of doing things it could help you import more personal data specifics into your rolling GRC work.
2.3 Existing security related risk management: Is it fit for privacy purposes?
No, it’s not, almost everywhere. The assessment of security related risk is pretty poor in general, and, if you don’t work in the military, law enforcement, transport, healthcare, education, pharma, energy, or a handful of other fields, it likely excludes any worthwhile consideration of impact on individuals, or groups of data subjects.
These were common soapboxes for me; inability to quantify risk and ignoring potential harm. The latter is what we’re interested in here (for plenty on the former you could start here or here)
Risk based scoping decisions
The GDPR is very clear: You need a consistent risk-based way prioritise work, defend scope exclusions, justify your legitimate interests, guide security control selection, evidence progress towards compliance, and implement effective incident management including necessary notifications.
That point about scope exclusions is often underestimated, but it’s absolutely vital. You have to do a robust Data Protection Impact Assessment on processing likely to result in a high risk and if residual risk is still high after allowing for controls, you have to report that to the regulator (see this diagram from the Article 29 Working Party DPIA guidelines, WP248, pg6 for details). You can also, if in doubt, invite direct input from potentially impacted data subjects to gauge the scale and immediacy of risks, as well as their tolerance for them.

You also need to gauge whether there is a ‘likely’ ‘high risk’ when deciding whether to notify data subjects of a breach (Article 34). Here’s a one pager [PDF] from law firm Bird & Bird on breach notification.
In both cases – and this is harder to make stick than it appears because we are all so used to dealing with org-centric data security related risk – that’s a likely high risk to the rights and freedoms of data subjects, not to the health of the P&L and quarterly results.
Unavoidable and critical steps:
- Agreeing standardised benchmarks for ‘likely’ and ‘high risk’ with all data protection stakeholders
- Designing a triage mechanism that’s quick, easy, and reliable enough to assess all of your processing without killing staff involved
- Producing consistent triage output that enables you to defend exclusion of processing you DON’T go on to assess in greater detail, or breaches you DON’T decide to notify to data subjects.
- Ensuring the triage mechanism is reusable, so you can refresh the inherent risk heat map over time instead of starting from scratch every couple of years, doing it on a last-minute ad hoc basis when there’s some big IT change, or cobbling something together after an audit/breach.
Risk reports
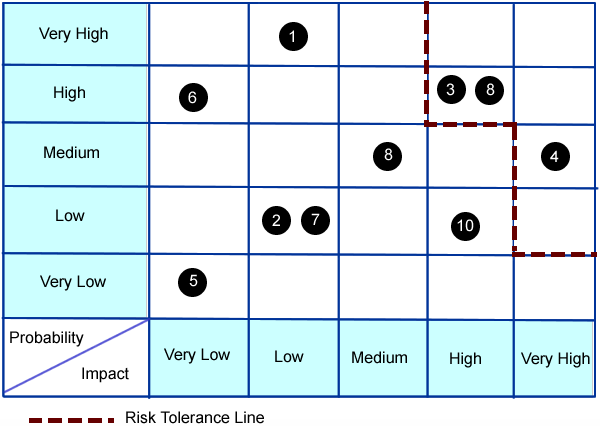
In that matrix, so ubiquitous it could come from anywhere, we don’t have any sign of individual harm. Regardless of axis labels the vast majority of the management team will assume the impact scale is monetary. This picture represents the sum total of risk data communicated in most board level reports. Changing decades old financial risk models to integrate risk to individuals will take a while to sell and longer to bed in. If the leadership team can’t make time to drill down to a considerable amount of extra detail, at least for the first few weeks, then privacy related risk management will never mature.
Here’s a table used by a security solution vendor to assess HiPAA risks.
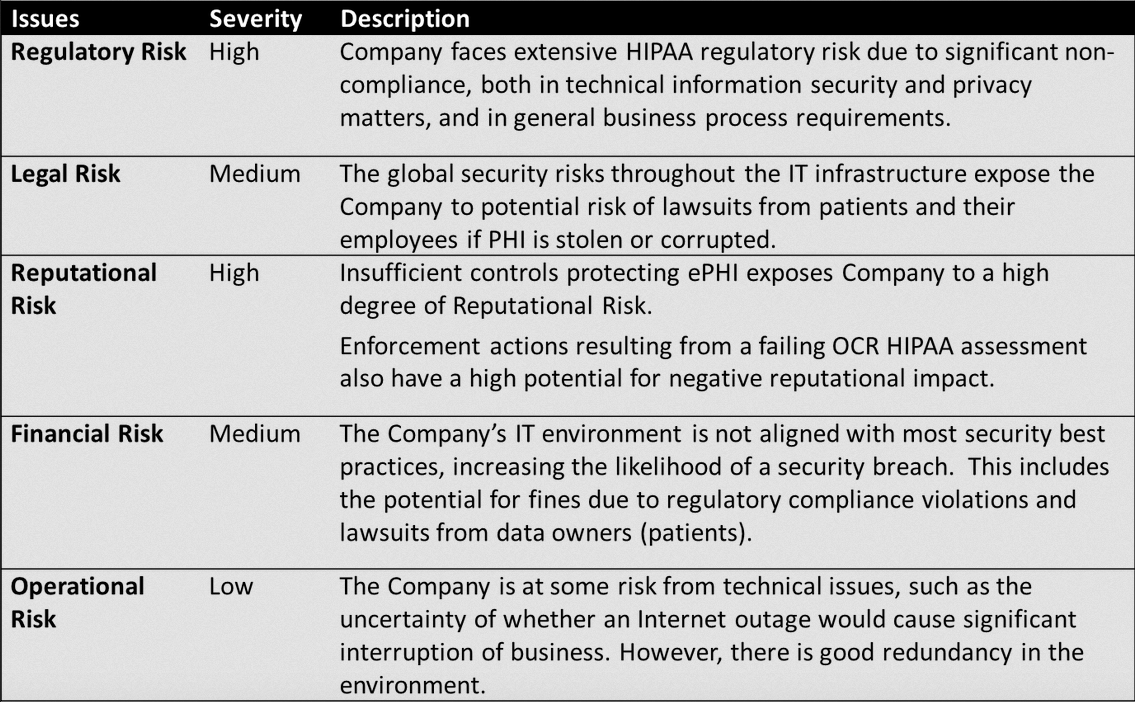
As you can see, it isn’t a great deal more promising. This is representative, barring a tidge more detail, of the vast majority of more diligent organisations. It will often come with a guesstimated translation into dollar value (often essential to make it fit into the risk management software or GRC tool), but it still focuses solely on the organisation. Impact as a function of subject request management cost, incident investigation cost, notification cost, credit check cost, regulatory fines, legal penalties, lost sales, lost customers, and reduced share price.
While it’s essential for an organisation to understand its own risks, we cannot get away with this any more. We have to inject and document explicit consideration of data subjects singly and in groups who might share some of the impact. That’s what this means:

Scaling privacy risks
This is qualitative guidance on Data Protection Impact Assessments (DPIAs) and what constitutes a high risk from the Article 29 Working Party (WP29). It provides some help, but it’s a blunt tool. If you hit two or more of the criteria listed then the WP29 consider it a likely high risk.
In most cases, a data controller can consider that a processing meeting two criteria would require a DPIA to be carried out. In general, the WP29 considers that the more criteria are met by the processing, the more likely it is to present a high risk to the rights and freedoms of data subjects, and therefore to require a DPIA, regardless of the measures which the controller envisages to adopt.
However, in some cases, a data controller can consider that a processing meeting only one of these criteria requires a DPIA. – Page 11, WP29, WP248
This ENISA (European Union Agency for Network and Information Security) approach to impact and likelihood assessment has a go at giving risks a numerical value. The methodology and other ENISA data security related resources are worth a look although a few years old now (2013), and almost entirely focused on breaches caused by broken security controls, as opposed to accidents or misuse of permitted access. Here’s an extract from their risk matrix.

Then there are the PIA resources from CNIL (Commission Nationale de l’Informatique et des Libertés) the French data protection authority. They provide guidance on methodologies, a free DPIA template, and a knowledge base, but most of the data gathering in their template involves open questions and free-form responses. It’s hard to avoid some of that with something like privacy risk, but we should all be standardising responses wherever we can to enable central analysis and comparison. One can always re-inject something more qualitative if there are scoping tie breakers that need more context.
Even allowing for those constructive steers, we need better measures and metrics to compare, scale, multiply, and aggregate impact while we meaningfully estimate the probability of real world outcomes. But at the same time that has to be sustainable and repeatable without an army of highly paid consultants, or killing staff. There are some smart ways to do that with common tools and no magic wand, things you might have got hold of from one of the really experienced data protection professionals out there (I have some of my own tips to share in another post), but it also needs some fresh thinking from the community as a whole.
Circling back to the ISO27001 discussion: How GDPR compliant are your pre-existing risk assessment and risk tolerance documents looking now? If the answer is ‘not much’ what can you do about it? Perhaps revisit the obviously high risk processing, use the WP29 guidance on absolute criteria as a steer, and consider some other straightforward benchmarks for inherent privacy risk (see the bullets below). At this stage we’re looking at potential to cause risk – if there’s little to no potential risk, why waste time in early phases gathering pages of details?
For example:
- Numbers of records stored in aggregate, or numbers of records processed or added per week/month/year. E.g. 0-1,000 records, 1,001-5,000 records, 5,001-10,000 records, 10,001
- Numbers of 3rd parties involved in specific processing and/or number of different personal data processing purposes a supplier performs across your organisation e.g. a supplier like Salesforce or Experian might have multiple service agreements, most of which involve personal client or staff data, under a master framework contract. Complexity of a supply arrangement increases risk.
- The number of different data types processed (e.g. different special categories + convictions data + child data + card/bank details)
- The number of vendor staff members involved in servicing the personal data processing requirements (a factor proven by risk firm VivoSecurity to map to levels of risk
- The number of your staff who have privileged access, change access, or view access for that data.
Then branch questions and standardise responses as hard as you can (I can’t stress that enough). Minimising the effort and time needed to answer questions, or populate a form, and having ability to compare and analyse results is absolutely vital to make this work.
Then, and only then, if the inherent risk indicates a need to dig further, have a go with tools from ENISA, CNIL, or your own templates, and don’t be afraid to prioritise further based on initial responses. No-one, not even the regulator, thinks you can magic up time or resources to get all this done (although, to be fair, you had at least 2 years concrete warning this was coming, plus another quarter year since May 25th).
Even having said all that, everybody is in the same boat, so it’s perfectly fine to make a best efforts attempt on the first assessment cycle as long as you take into account real breach scenarios and potential short/medium/long-term impact on data subjects…and you document that…and you define who is formally responsible and accountable for doing something about whatever you uncover…and you put processes in place to assess again on a reasonable cycle; for new suppliers, for personal data related change, and for any other bright new processing ideas.
Bigger challenges like enabling people to manage their own risks and the risk|reward myth
Data subjects don’t own their data and they often don’t understand data sharing implications, so they frequently can’t make an informed choice when asked to check boxes and click through reams of detailed text to access something online. Especially when sharing data with tech giants in the social media, online retail, internet search, or ancestry DNA business…to name a few. There are a multitude of outstanding cases relating to various more or less transparent uses of data in those worlds.
People doubly don’t get it when data is passed on to one or more institutional friends or partners, or a.n.other firm via the ad tech auction process…
…but data subjects definitely do own their privacy risks.
Here’s one of the first stories after the news broke that Glaxo was investing in personal DNA profiling firm 23andMe in return for exclusive rights to anonymised DNA data and significant quantities of the real crown jewels: associated phenotype data (the kind of personal health context 23andMe users provided via constant surveys and other requests for info).

Yes, people were only included in research if they gave consent, but there was a significant backlash based on the fact that many didn’t feel they provided INFORMED consent. People who were curious to find out if they had interesting roots, either didn’t realise they were one of the 80% who consented, or they wanted to change their minds when they found out they were providing a data goldmine to big pharma. In GDPR terms this isn’t just ‘too bad, so sad’ this is grounds for individuals to challenge whether notification and consent mechanisms were sufficiently straightforward and transparent.
No matter your ethical feelings about this, especially bearing in mind the massive benefits for everyone that can come from big data analysis in more classical modes of medical research, the potential impact on data subjects can’t be denied. Nor can our responsibility to help people assess and manage their risks by being crystal clear about planned data usage, who else we’ll involve, and the rights they have to question and challenge. Things we need to tell them before we take and keep their data (see GDPR Articles 13 for details)
No individual organisation is going to fill the glaring gap in current means to quantifiably scale virtual personal data risk. Even the legal system is hobbling useful attempts with a centuries old focus on direct and immediate financial or physical harm.
Arguably a dangerous nonsense given the global monetisation of data and the conversion of data into lucrative units of influence both by and for corporations, governments, and criminals (here’s my meaty post on the Facebook, Cambridge Analytica, and more general campaign and ad tech analytics fun). All set against a backdrop of increasingly unavoidable digitisation (financially, professionally, socially, educationally, governmentally, public spacially, smart home-wise, and health-wise).
Most internet users treat their virtual identities and virtual spaces as indivisible extensions of themselves and their homes. If virtual selves and contents of personal virtual spaces (like browser histories, password stores, inboxes, and calendars) are commodities to be traded, there should be commensurate ownership rights and legal protections. That isn’t the case, but it may well become so with far more explicit and transparent transactional models being proposed for data sharing in exchange for services, money, or goods.
Steps towards a more fit for purpose privacy future?
On 20th January 2018 some privacy and data protection practitioners, including yours truly, Joined Dr Isabel Wagner and Eerke Boiten at De Montfort University’s Cyber Technology Institute for a workshop related to this.

Having a common language and means to discuss and scale personal data risks would have far-reaching positive implications far beyond effort to comply with the GDPR, especially for things like online abuse, so I was delighted to contribute and will watch Isobel’s space with avid interest while that moves on.
Big data bigger risks?
So, when vendors tell you that their security GRC or data security tool is guaranteed to make you GDPR compliant, or that it is essential to encrypt ALL the at-rest things, they are telling porkie pies. It all depends on context, context specific configuration, detail of your local threats, the related vulnerabilities, likely incident impacts, and the relative severity of risk associated with current gaps in control.
But there’s also big data…sorry <clears throat> :

- 1,209,600 new data-producing social media users each day.
- 656 million tweets per day
- More than four million hours of content uploaded to YouTube every day, with users watching 5.97 billion hours of YouTube videos each day.
- 67,305,600 Instagram posts uploaded each day,
- There are over two billion monthly active Facebook users, compared to 1.44 billion at the start of 2015 and 1.65 at the start of 2016.
- Facebook has 1.32 billion daily active users on average as of June 2017.
- 4.3 billion Facebook messages posted daily
- 5.75 billion Facebook likes every day.
- 22 billion texts sent every day.
- 5.2 billion daily Google Searches in 2017.
Jeff Schultz, Oct 16 2017, “How Much Data Is Created on the Internet Each Day?” DZone
There’s gold in them thar data oceans and every organisation has been trawling them like their lives depend on it. Giant hauls have cumulatively played fast and loose with pre-existing data protection rules and frequently exceeded means to collate, categorise, analyse, and granularly manage data scooped. But why would folk grab the data if they had no use for it?! Commercial FOMO played a massive role, but more is explored in the report ‘Marketing in the Dark: How companies are dealing with dark data‘ (DARK DATA – Duh Duh Duuuuh, as if we needed another foreboding buzzphrase, but I digress). Here’s a short quote referring to the fact that folk have oceans of data accumulated that they’ve made no real inroads to use…and leading onto ways that IBM can probably help them:

Most data sciencey types will go pretty pale when you ask them where they got the data in their giant pot. Often they will be able to tell you which systems they sync with , but ask them for a data dictionary for each individual source, ask if they can single out subsets originally collected from a given source at a given point in time, then ask if they can cease or restrict processing based upon a withdrawal of consent, a request to forget, or a change in lawful basis because of the next exciting analytics/machine learning/AI project or access granted to a 3rd party. Yeah…um…well…
I explore that bulk data and interconnected database risk management and control challenge in more detail in this post. Yes it’s hard, but hard isn’t an excuse for throwing people under a bus, especially if difficulty is linked to potentially illegal and indiscriminate historical data collection. There needs to be some diligence retrofitted around inputs to bulk data stores and means have to be established to either reliably pseudonymise/anonymise data, granularly manage it without disrupting the store as a whole, or super senior signatures need to be put on an application to temporarily or more permanently tolerate the realistic risk of a related breach…cos no-one is nosing round Amazon buckets just in case someone left a lid off:
Octoly, French marketing firm leaks 12,000 records belonging to social media influencers including all data about them collected by the firm
Spyfone, spy software to track phone user activity that was aimed at parents. Leaked Terabytes of data linked to at least 2,200 current user profiles
Robocent, robocalling firm leaks 2,600 voter call recordings and sets of voter details.
Alteryx, an ad tech firm, leaked records linked to 123 million Americans. Data from their partner Experian, the credit reference agency, paired with publicly available data from the US Census. Here’s how Dan O’Sullivan from UpGuard (the firm who initially found and investigated the exposed data) articulated the risk, bearing in mind there was a record there for pretty much every adult American.
From home addresses and contact information, to mortgage ownership and financial histories, to very specific analysis of purchasing behavior, the exposed data constitutes a remarkably invasive glimpse into the lives of American consumers. While, in the words of Experian, “protecting consumers is our top priority,” the accumulation of this data in “compliance with legal guidelines,” only to then see it left downloadable on the public internet, exposes affected consumers to large-scale misuse of their information – whether through spamming and unwanted direct marketing, organized fraud techniques like “phantom debt collection,” or through the use of personal details for identity theft and security verification.
However, even against that backdrop, assessed risks have not, as discussed at length in the first post, suddenly changed, with the exception of the potential sanctions (something I’ll discuss more in the final instalment). If the original risk assessment, and any subsequent assessment was fit for purpose and took potential harm to individuals into account, the GDPR should not be driving your organisation in new and terrifying security directions. If it wasn’t, or if the profit blinded you to folk on Shodan rummaging round in your buckets, then the threat of new sanctions may well be causing some discomfort.
Summing up and back to first steps
So how does your security and data protection world look in the light of this monster post? Hopefully not much different given the hard work you’ve done to understand your processing, lawfulness of that, transparency of your notices to data subjects, how well third parties are doing with all that, associated risks, and required control, but just in case, here’s a recap on some things to review:
Just like any security strategy is about your organisation, your data processing, your vulnerabilities, your environmental and external threats and the same again for your suppliers. It is about the impact of a personal data breach, or another security related data problem, whenever those things might impact the rights and freedoms of your staff, your clients, or individuals caught up in your data processing supply chain.
- Identify all of the appropriate security and data protection stakeholders
- Review your security policy, strategy, risk appetite, and existing risk assessments.
- Update to explicitly include risk to data subjects
- Define triage criteria and mechanisms.
- Review security metrics and supplement with updated benchmarks for data protection
- Integrate with existing change, vendor due diligence, and vendor assessment processes wherever possible to deduplicate work.
- Work with the Data Protection specialists to ensure security tools and processes don’t themselves breach personal data protection requirements (e.g. 3rd party device fingerprinting, or user behaviour analytics) if they can’t be justified as a legitimate interest (see below).

Then switch back to BAU, if BAU is a risk based strategy that you would be happy to describe to the ICO after a breach…or weave the data security gaps you always knew about, but didn’t have motivation and money to fix, into that GDPR plan.
Featured Image Copyright: eenevski / 123RF Stock Photo