Do you have any online profiles or posts featuring those 4 magic characters: G D P R? If so, whether you are a business decision maker, IT body, security body, charity boss, employed data protection pro, or job seeking data protection pro (less and less likely), you are almost certainly drowning in a flood of silver bullety vendor pitches.
BUT, underneath that increasing frustration, you are almost certainly in the market for a technical solution or two. A shopping spree feeding a many headed tech industry hydra claiming GDPR value-add with little or no buyer-friendly, or regulation relevant, context.

Image links to full Article 30 wording
My Dad had a vaguely NSFW* saying: “All fur coat and no knickers”. That’s a pretty accurate description of marketing copy vs functional reality for some kit. Conversely, there are some great tools. Ones that do exactly what it says on the tin, but too many customers ignore the maturity and medium-term investment needed to realise advertised benefits.
When it comes to automated data discovery – not to be confused with data mapping*, although there’s a tooling and process crossover – it’s tempting to assume it will take care of Article 30: The requirement for data controllers and processors to keep a record of all personal data processing. Nailing that is an automatic accountability win and there are many other controls that directly or indirectly benefit.
Here I’m arguing at fair length that it won’t, for most firms…at least not in the time left to demonstrate robust progress towards compliance. An opinion informed by many years watching shelfware accumulate and working to ensure tech procurement respects real requirements and operational reality.
Machine stupidity
https://twitter.com/mims/status/875427817776959491
There’s no doubt that technology can help tame the mountains of information you need to collect, categorise, analyse, prioritise, and act upon (or validate a reason for not acting upon), no matter the length of the likely journey between your current data protection state and where you think you want to be by May 2018.
The problem is, technology ain’t intelligent, no matter the machine learning and AI related blurbs. Out of the box it knows nothing about YOUR business, your data uses, your data handling practices, your specialist systems, and your third parties. You have to tell that to the tool, or add it offline.
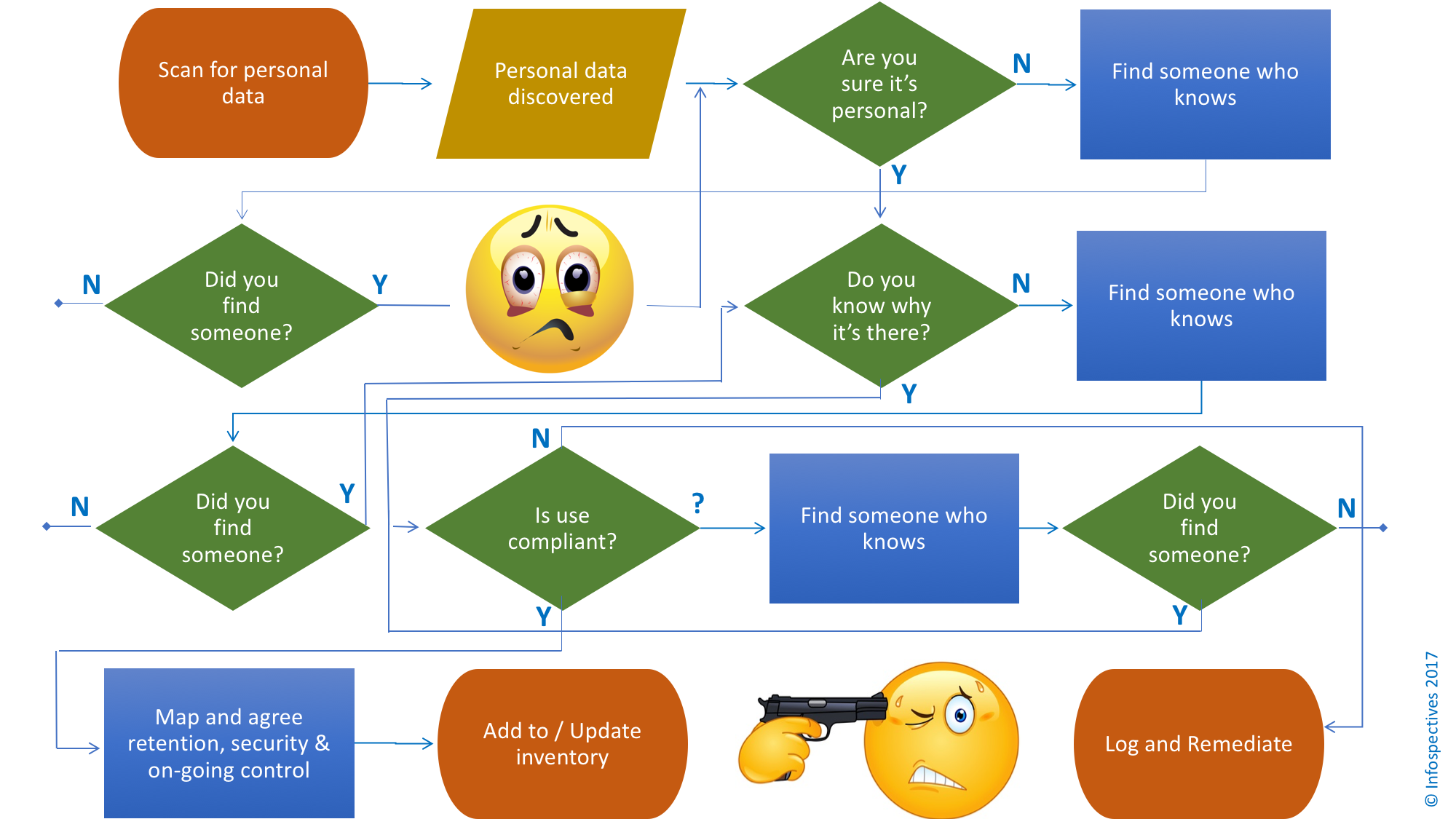
Out of the box it will guess, using more or less vanilla variables, what’s personal, sensitive, or secret. You are then left to weed out falsely positive findings and ones that are positively false, feeding local knowledge back in to tune. Even when you have some clean results it won’t know the difference between an ad hoc issue (that one time a personal data list made it onto an open file share) and a systemic issue (folk using that file share as a workaround to distribute a weekly system extract). Nor will it know why data is there, whether processing is compliant with collection purposes, or if data is being handled securely.
Data is not a religion. It is not a panacea. Data isn’t going to tell you what data you need to listen to. Humans are going to tell you what data you need to listen to.
Rik Kirkland, ‘The role of expertise and judgment in a data-driven world’ McKinsey.com – May 2017
Establishing all that takes a hugely underestimated amount of deep local knowledge and time. It’s an oft ignored fact of more general tool ownership life. An expensive accident waiting to happen…IF you don’t do your due diligence and have people on point who are accountable, adequately knowledgeable, and available to tune, triage, and treat outputs….plus a budget and plan that takes all of that into account.

Not all solutions are created equal. Some can automatically tackle more than the first 2 boxes in that process, and most can add significantly more value over time (depending on the effort you put in). Others include means to automatically stop unauthorised data transfers and even redact/encrypt data on the fly. But, when you find yourself staring at initial output – a set of ‘issues’ both audit and the board might see as an urgent to-do list – it can quickly distract from other vital work and become a stick to hit you with when time is perilously short.
Only a quarter of organizations with threat intelligence capabilities feel that it’s delivering on business objectives
Tara Seals, on ISF’s Threat Intelligence: React and Prepare report, InfoSecurity Magazine – June 2017
For context, consider historical problems making usable sense of Intrusion Detection System output, the ongoing fun making successful operational use of many threat intelligence offerings, and the evolving joy relating to expected strategic value many businesses can’t extract from data analytics solutions.
Or, for those in the GRC space, consider how complete, up-to-date, and useful IT asset inventories and GRC tools currently are. Then, if they are fit for purpose and adding real risk management value, consider what the overhead was to get them into – and keep them in – that state.
…the pitfalls are real. Critically, an analytics-enabled transformation is as much about a cultural change as it is about parsing the data and putting in place advanced tools. “This is something I got wrong,” – Jeff Immelt, CEO of GE,
Nicolaus Henke, Ari Libarikian, and Bill Wiseman, ‘Straight Talk About Big Data’ McKinsey.com – Oct 2016
Which pieces of the data processing puzzle?
And that’s still only part of the tech acquisition equation. An equation that may still result in a positive for your organisation. The question is: How positive?
Does the tool just look at more or less limited metadata, or does it look at file and record content? Depending on the answer, can it do what you hoped it would in terms of categorisation, analysis, and control?
How much of your information governance picture will the box or boxes paint? Will they work on structured data (e.g. databases), unstructured data (e.g. email and file stores), bespoke systems, legacy systems, desktops, laptops, smartphones, CCTV, XaaS cloud hosted data, mainframes, backup solutions, removable media…and the same again for your processors?
Collecting limited metadata and excluding some data subsets, isn’t necessarily a show stopper. BUT, in order to understand, articulate, and manage residual risk, you have to do robust enough due diligence to throughly understand tool capabilities, and confirm what is and isn’t in functional, technical, and support scope.
Even more than that, do you know who will support and maintain it on-going? And how will it will feed into future data protection GRC and related remediation? If you don’t sort that, it’s like kicking a ball down the pitch with no-one to pick it up (except the opposition). More generally, are you aiming for a one time blitz to feed the compliance machine, or is it intended to be a repeatable and sustainable improvement to your information governance world?
The counterpoint to all of that is the extent of the data control mess you are currently in and the continuing fogginess around how much GDPR related control is enough. For organisations with good internal and supplier data protection controls, well structured and current information asset inventories, and meaningful data governance RACIs, there’s much, much less pain, and far more to gain.
For everyone else the theoretical lure of a system sorting this out for you, a way to evidence that something is being done, is dangerously powerful. Humans are terrible at balancing instant gratification against longer-term pain. And when it comes to blinky boxes (allowing for pre-existing control maturity and influence wielded by your DP or security boss) buying a tech fix, for a people and process problem, stores up enormous angst …angst that might not be felt until the GDPR countdown gets loud enough to rob you and your board of sleep.
So what’s to be done? Especially when, as predictably as day follows night, your GDPR journey kicks off with one huge question:
Where do we start?

Copyright : lightwise
Thoroughly and finally pinning my colours to the mast, it’s almost certainly not (based on everything above), with automated data discovery. For many firms it wouldn’t even be a cost-effective bolt-on to other first phase activity.
The role of automated data discovery, at base, is to assess RESIDUAL data governance risk (the risk that remains when you understand your core data processing and have a reasonable handle on your data RACI). It can also help maintain control over time. Value-add that many don’t yet have the means to realise.
But you don’t have to take my word for this. Ask vendors for some sample tool output and translate it into something relevant to you, or (if quick and simple) take them up on the offer of a free trial. Then work with business and IT stakeholders to gather sufficient information to validate findings. Either confirm compliance with sufficient detail to create a useful asset inventory entry (see Article 30 for details), or log findings and allocate an owner if things need to be fixed.
You can extrapolate the likely overhead for triage and investigation by multiplying the number of alerts the tool typically generates by the time all that took. Remembering to add in effort to get the tool through internal/supplier IT change management and then tune it. As compensation, that can be incredibly helpful to highlight other GDPR gaps and give you a rough feel for your information governance maturity.
If you do then decide to purchase a solution and diligently record all your tuning, triage, and investigative work, effort will tail off significantly over time. But given we have less than 12 months to do far more than find data, don’t you need certainty right now, rather than potentially painful steps to prepare a tool to be useful later?
Other options
Tackling the big question more generally (at a very high level), this is what I recommend: Start with what you already know. Focus on data processing that’s obviously high risk.
First feel around the edges of the whole personal data picture. You don’t need tools to put existing IT, legal, procurement, marketing, HR, and other stakeholders in a room. Get them to list the highest volume, highest throughput, and most sensitive data collection and processing, along with the key systems and suppliers involved.
Start with your main data collection points (web, phone, face to face) and remind yourself why data was collected. Then link primary related processing to that starting point. Most of what you can and can’t do with a set of data grows from the legal basis for processing and the purpose(s) initially agreed with data subjects. Backed up by detail in contracts, privacy notices, and any compliant justifications for a legitimate interest.
If you find the concepts of purpose and processing too abstract, you should read this post by Denmark based privacy pro Tim Clements. It brilliantly breaks them down into what matters and why, with terms that will make real sense to stakeholders.
Maybe you will outsource that exercise to a consultancy (all of them have a gap analysis offering), but be very conscious of time and expense. Even if you don’t have a head start with pre-existing PIAs and other GRC info, there are some obvious priorities you don’t need a consultant to tell you to fix (e.g. updating policies, privacy notices, and supplier contracts. Improving subject request processes. Doing better with data retention. Rethinking marketing consent. Reviewing what you can and do encrypt or anonymise).
When you’ve drafted that view it will almost certainly represent 70-80% of your personal data estate and the associated inherent risk to data subjects and your organisation

A conceptual take on a retail data asset framework. Data assets (customers by product category) and data sets (by product lines), flowing from collection points through core then secondary processes. Logically grouping purposes, collection mechanisms, processes, and process owners
At the same time, crucially, nail your top-down data RACI, so you can bring the right quantity of the right people (from all impacted stakeholder groups), along for the ride. In tandem, applying agile principles (small ‘a’), you need to agree a business-wide framework to capture, categorise, and map identified data assets. Starting with basics (e.g. What is one? Hint: it’s never an application or server – those are data containers and means to process that are attached to assets and processes). You also need to agree your benchmarks for inherent risk (e.g. data volume, transaction numbers, special data classes, child data, convictions data, non-EEA location). Remembering a DPIA only has to be performed on high risk processing.
That gives you your first priorities. A framework to inform quick wins, information asset inventory acquisition/configuration, and strategic plans for other key changes.
On-going mapping and discovery will validate and widen that scope, allowing you to identify other priorities. As you delve into the less known knowns, you can build on intelligence and improvement plans for your core processing. Mapping other data sets and processes to the growing framework. Linking to known collection points, parent assets, core processes, and assessed controls…or logging strays for further assessment – valuable economies of scale.
There’s mountains of detail behind things covered in this last section, but I’ll leave that for another time…
…except to reiterate one point, because it bears frequent repetition (count the times it said “Find someone who knows” in that proces flow): If you haven’t found the right stakeholders and fostered buy-in (including formal assignment of accountability), no amount of mega per diem superstars or tools will sort this.
*DEFINITIONS and ACRONYMS:
Data Mapping – Understanding the personal data you collect and process, and the journey that data takes, both internally and with third parties, until it is deleted or anonymised.
Or, to quote guidance on mapping from the Information Commissioner for the Isle of Mann, tackling the 5 Ws:
- WHY … is personal data processed?
- WHOSE … personal data is processed?
- WHAT … personal data is processed?
- WHEN … is personal data processed?
- WHERE … is personal data processed? .
Data Discovery – Finding, analysing, categorising, and sometimes controlling personal data, often via technical means, to create, complete, or maintain accuracy of your data asset inventory.
Combined purpose of both exercises: To have sufficient information to reliably confirm (or trigger additional assessment of) the legality, transparency, fairness, and security of personal data collection, processing, and disposal. Enabling an organisation to respond effectively to subject requests, scope and prioritise activity required to address control gaps, understand and manage residual risk, more accurately assess incident impact, improve incident response, and sustain that over time.
Shelfware: Technology that never does the job it was bought to do. In effect remaining on the shelf.
DLP: Data Loss Protection/Prevention
DPIA: Data Protection Impact Assessment (GDPR terminology)
GRC: Governance Risk and Compliance
NSFW: Not Safe For Work
PIA: Privacy Impact Assessment
RACI: A record of who is Responsible, Accountable, Consulted, and Informed. Often applied to operational processes, risks, and controls, including contributory activity and oversight.
Caveats: Definitions are my own, based on usage of terms in this post. I am not a lawyer, so nothing here should be construed as legal advice. I am also a recent privacy convert following a long career in IT and InfoSec GRC. For the past year I have been dedicated to research, strategy, and planning for GDPR and more general data protection. For those who follow the blog, that’s why there has been a blogging hiaitus. I only claim expertise in transferable GRC skills and only offer opinions and advice based on experience, or good borrowed evidence. For everything else I can call on a number of trusted advisors (one of whom reviewed this post) if I need to check my legal and regulatory homework.